
In this article, we will learn about the decision trees and random forest algorithms. Also, we will address vital questions like what is a decision tree? What are random forest algorithms, their application, and decision tree vs. random forest algorithms?
What is Decision Tree?
Decision trees are incredible and famous devices for classification and prediction. Decision trees speak to rules, which can be figured out by people and utilized in an information framework, for example, the database. Moreover, the Decision tree model is a progressive model and it is composed of several nodes: root node, internal decision nodes, and terminal node or leaf node. It is a graphical portrayal of tree-like structure with every possible arrangement. Also, it assists with arriving at a decision dependent on specific conditions. It will be more evident when we discuss Decision tree vs. random forest algorithms. Let us take a practical example.
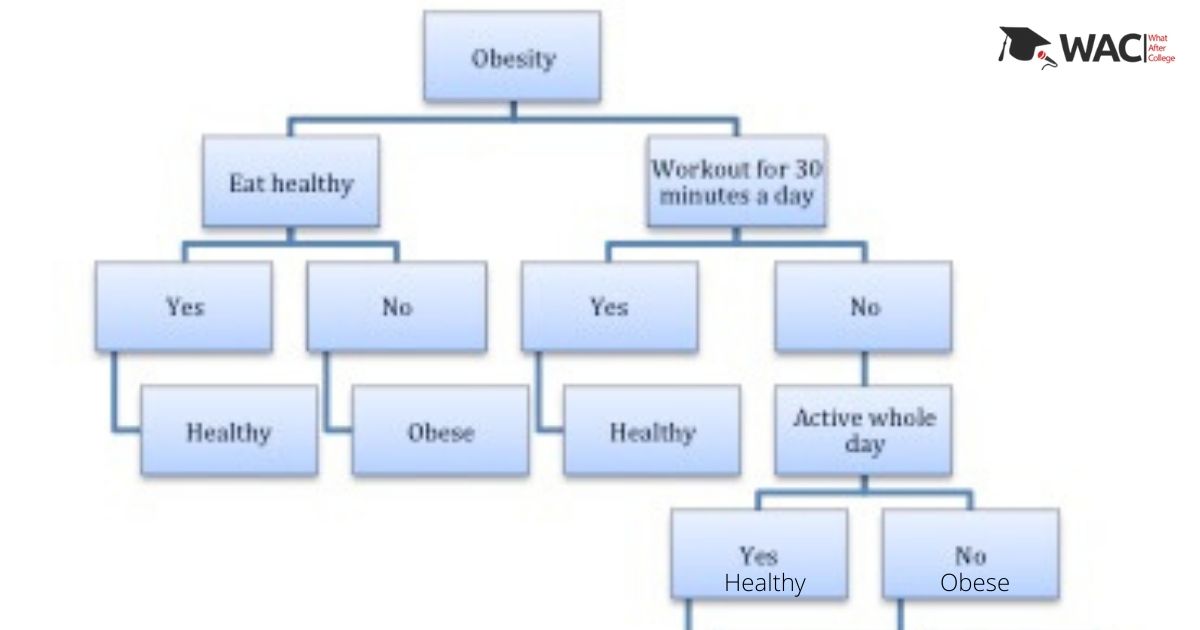
In the above classification decision tree example, Obesity is the root node; workout for 30 minutes a day and eat healthily are decision nodes. Healthy and obese are terminal nodes.
What are random forest algorithms?
As the name suggests, Random forest algorithms are the clusters (forests) of randomized decision tree algorithms where each decision tree gives their vote for the prediction of the target variable. The majority of the votes are considered to be the final output for the target variable for better accuracy. Additionally, it is also applicable to both classification and regression models.
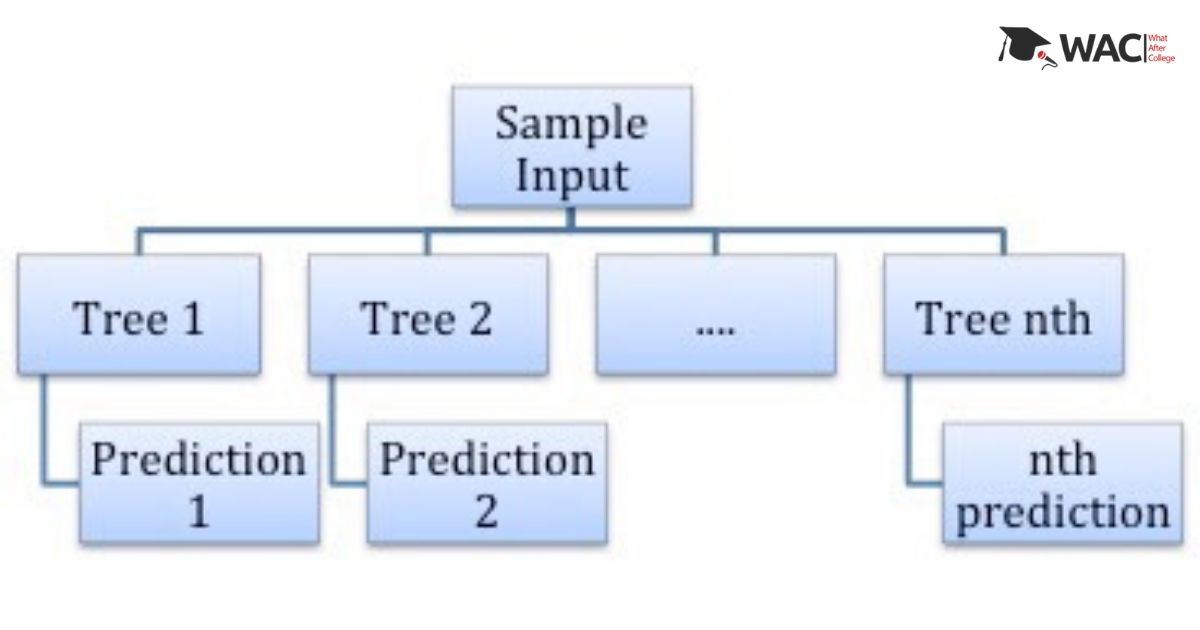
This is the basic structure of a random forest algorithm, where it takes consideration of instances individually. All the predictions (1, 2 up to nth decision tree) are then averaged out to give the random forest prediction.
Advantages and Disadvantages
When it comes to Decision Tree vs. random forest algorithms, let’s discuss a few factors to make it more explicit.
Decision Tree:
(Advantages)
- Easy to understand the decision rules.
- No need to select unimodal training data, easy to include a range of categorical data.
- It does not require much data analysis.
- Need not require predictions of the distribution of data.
- Helpful in the identification of hidden patterns in the data set.
(Disadvantages)
- It overfits training data, which gives bad results further.
- Unpredictable beyond the minimum and maximum training data limits of the response variables.
- It does not provide global optimize optimization, which is a major drawback.
Random Forest Tree:
(Advantages)
- It is a better option for accurate predictions for multiple applications.
- Measuring the importance of each characteristic with respect to the training data set.
- Compatible with missing data for better accuracy.
- Capacity to handle multiple input features.
- Also, Effective on large datasets.
(Disadvantages)
- A little complex to understand.
- Sometimes it fits with noisy regression or classification.
Applications: Decision tree vs. Random forest algorithms

Decision Tree:
- Spam email analysis and filtration.
- Very crucial to detect diseases, especially in the recent coronavirus outbreak, the decision tree is the most used algorithm to predict the COVID-19.
Random forest algorithms:
- Bioinformatics uses random forest algorithms for complex data analysis.
- High dimensional video segmentation
- Pixel analysis for image categorization.
To conclude, both the algorithms are used according to their applications and we can comprehend Decision tree vs. random forest algorithms explicitly with all the information mentioned above.
Happy learning!
All you need to know about Machine Learning
Learn Machine Learning
| Top 7 Machine Learning University/ Colleges in India | Top 7 Training Institutes of Machine Learning |
| Top 7 Online Machine Learning Training Programs | Top 7 Certification Courses of Machine Learning |
Learn Machine Learning with WAC
| Machine Learning Webinars | Machine Learning Workshops |
| Machine Learning Summer Training | Machine Learning One-on-One Training |
| Machine Learning Online Summer Training | Machine Learning Recorded Training |
Other Skills in Demand
| Artificial Intelligence | Data Science |
| Digital Marketing | Business Analytics |
| Big Data | Internet of Things |
| Python Programming | Robotics & Embedded System |
| Android App Development | Machine Learning |